- Privacy Policy
Home » Quantitative Research – Methods, Types and Analysis

Quantitative Research – Methods, Types and Analysis
Table of Contents
Quantitative research is a systematic investigation that primarily focuses on quantifying data, variables, and relationships. It involves the use of statistical, mathematical, and computational techniques to collect and analyze data. Quantitative research is often used to establish patterns, test hypotheses, and make predictions. It is widely applied in fields such as psychology, sociology, economics, health sciences, and education.

Quantitative Research
Quantitative research is a research approach that seeks to quantify data and generalize results from a sample to a larger population. It relies on structured data collection methods and employs statistical analysis to interpret results. This type of research is objective, and findings are typically presented in numerical form, allowing for comparison and generalization.
Key Characteristics of Quantitative Research :
- Objective : Focuses on numbers and measurable variables rather than subjective opinions.
- Structured : Employs well-defined research questions, hypotheses, and data collection methods.
- Statistical : Utilizes statistical tools to analyze data and validate findings.
- Replicable : Enables repetition of the study to verify results and increase reliability.
Example : A survey on the correlation between exercise frequency and stress levels among adults, using a Likert scale to measure responses.
Types of Quantitative Research
Quantitative research can be categorized into several types, each serving a specific purpose. The most common types include descriptive , correlational , experimental , and causal-comparative research.
1. Descriptive Research
Definition : Descriptive research describes characteristics or behaviors of a population without examining relationships or causes. It provides a snapshot of current conditions or attitudes.
Purpose : To gather information and create an overview of a particular phenomenon, population, or condition.
Example : A survey describing the demographics and academic performance of students at a university.
2. Correlational Research
Definition : Correlational research examines the relationship between two or more variables but does not imply causation. It analyzes patterns to determine if variables are associated or occur together.
Purpose : To identify associations or trends among variables without establishing cause and effect.
Example : Investigating the relationship between social media use and self-esteem among teenagers.
3. Experimental Research
Definition : Experimental research manipulates one or more independent variables to observe the effect on a dependent variable, establishing cause-and-effect relationships. This type of research involves control and experimental groups.
Purpose : To test hypotheses by isolating and controlling variables to establish causality.
Example : Testing the effect of a new medication on blood pressure by administering it to one group (experimental) and comparing it to a placebo group (control).
4. Causal-Comparative (Ex Post Facto) Research
Definition : Causal-comparative research investigates the cause-effect relationship between variables when experimental manipulation is not possible. It compares groups that differ on a particular variable to determine the effect of that variable.
Purpose : To explore cause-and-effect relationships retrospectively by comparing pre-existing groups.
Example : Studying the impact of different teaching methods on student performance by comparing classes taught with traditional versus technology-assisted instruction.
Quantitative Research Methods
Quantitative research methods focus on systematic data collection and analysis using structured techniques. Common methods include surveys , experiments , and observations .
Definition : Surveys are a popular quantitative method that involves asking participants standardized questions to collect data on their opinions, behaviors, or demographics. Surveys can be conducted via questionnaires, interviews, or online forms.
Purpose : To gather data from a large sample, allowing researchers to make inferences about the larger population.
Example : Conducting a survey to collect customer satisfaction data from a random sample of customers in a retail store.
Advantages :
- Cost-effective and time-efficient for large sample sizes.
- Provides structured data that is easy to analyze statistically.
Disadvantages :
- Limited depth, as responses are often restricted to specific options.
- Potential for response bias, where participants may not answer truthfully.
2. Experiments
Definition : Experiments involve manipulating one or more variables in a controlled environment to observe the effect on another variable. Experiments are often conducted in laboratories or controlled settings to maintain precision and limit external influences.
Purpose : To test hypotheses and establish cause-and-effect relationships.
Example : Conducting a laboratory experiment to test the effect of light exposure on sleep patterns.
- High level of control over variables.
- Establishes causality, which can support theory-building.
- Limited external validity, as findings may not always apply outside of the controlled setting.
- Ethical considerations may limit experimentation on certain subjects or groups.
3. Observations
Definition : Observational research involves systematically observing and recording behavior or events as they occur naturally, without interference. While often used in qualitative research, structured observational methods can yield quantitative data.
Purpose : To gather real-world data in a non-intrusive manner.
Example : Observing customer behavior in a store to track time spent in different areas and identify shopping patterns.
- Provides data on actual behaviors rather than self-reported responses.
- Useful for gathering data on situations where surveys or experiments may not be feasible.
- Observer bias may affect results.
- Can be time-consuming, especially if behaviors are infrequent or complex.
Data Collection Tools in Quantitative Research
Quantitative research relies on various tools to collect and quantify data, including:
- Questionnaires : Standardized forms with close-ended questions, often using scales (e.g., Likert scale) for responses.
- Tests and Assessments : Used to measure knowledge, skills, or other measurable attributes.
- Digital Tracking Tools : Software or digital applications that collect data, such as website traffic metrics or physiological monitoring devices.
Data Analysis in Quantitative Research
Data analysis in quantitative research involves statistical techniques to interpret numerical data and determine relationships or trends. Key techniques include descriptive statistics , inferential statistics , and correlation analysis .
1. Descriptive Statistics
Definition : Descriptive statistics summarize and organize data, providing basic information such as mean, median, mode, standard deviation, and range.
Purpose : To give an overview of the dataset, allowing researchers to understand general trends and distributions.
Example : Calculating the average test scores of students in a school to assess overall performance.
Common Measures :
- Mean : Average of all data points.
- Median : Middle value of an ordered dataset.
- Standard Deviation : Measure of variability around the mean.
2. Inferential Statistics
Definition : Inferential statistics allow researchers to make predictions or inferences about a population based on sample data. Techniques include hypothesis testing, t-tests, ANOVA, and regression analysis.
Purpose : To determine if observed results are statistically significant and can be generalized to a larger population.
Example : Using a t-test to compare average scores between two different teaching methods to see if one is significantly more effective.
Common Tests :
- t-Test : Compares the means of two groups to determine if they are statistically different.
- ANOVA (Analysis of Variance) : Compares means among three or more groups.
- Regression Analysis : Examines the relationship between independent and dependent variables.
3. Correlation Analysis
Definition : Correlation analysis measures the strength and direction of the relationship between two variables. It is used to determine if changes in one variable are associated with changes in another.
Purpose : To identify associations between variables without implying causation.
Example : Calculating the correlation coefficient between screen time and academic performance to determine if there is an association.
- Pearson Correlation Coefficient (r) : Measures linear correlation between two continuous variables.
- Spearman’s Rank Correlation : Measures correlation between two ranked variables.
Advantages and Disadvantages of Quantitative Research
- Objective : Minimizes researcher bias by focusing on numerical data.
- Generalizable : Findings from large, random samples can often be applied to a broader population.
- Replicable : Structured methods make it possible for other researchers to replicate studies and verify results.
Disadvantages
- Limited Depth : Quantitative research often lacks the depth of qualitative insights.
- Rigid Structure : Limited flexibility in data collection and analysis.
- Potential Bias : Response or sampling biases can affect results, especially in survey-based studies.
Tips for Conducting Effective Quantitative Research
- Define Clear Objectives : Develop specific research questions or hypotheses to guide the study.
- Choose the Right Method : Select a quantitative method that aligns with the research goals and type of data needed.
- Ensure Sample Representativeness : Use appropriate sampling techniques to ensure results can be generalized.
- Employ Proper Statistical Tools : Choose analysis techniques that match the nature of the data and research questions.
- Interpret Results Accurately : Avoid overgeneralizing findings and consider limitations when interpreting results.
Quantitative research provides a structured, objective approach to investigating research questions, allowing for statistical analysis, pattern recognition, and hypothesis testing. With methods like surveys, experiments, and observational studies, quantitative research offers valuable insights across diverse fields, from social sciences to healthcare. By applying rigorous statistical analysis, researchers can draw meaningful conclusions, contributing to the body of scientific knowledge and helping inform data-driven decisions.
- Creswell, J. W., & Creswell, J. D. (2018). Research Design: Qualitative, Quantitative, and Mixed Methods Approaches (5th ed.). SAGE Publications.
- Punch, K. F. (2014). Introduction to Social Research: Quantitative and Qualitative Approaches (3rd ed.). SAGE Publications.
- Field, A. (2013). Discovering Statistics Using IBM SPSS Statistics (4th ed.). SAGE Publications.
- Trochim, W. M., & Donnelly, J. P. (2008). The Research Methods Knowledge Base (3rd ed.). Cengage Learning.
- Babbie, E. R. (2021). The Practice of Social Research (15th ed.). Cengage Learning.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Applied Research – Types, Methods and Examples

Textual Analysis – Types, Examples and Guide

Ethnographic Research -Types, Methods and Guide

Explanatory Research – Types, Methods, Guide

Research Methods – Types, Examples and Guide

Basic Research – Types, Methods and Examples
Data & Finance for Work & Life

Data Analysis: Types, Methods & Techniques (a Complete List)
( Updated Version )
While the term sounds intimidating, “data analysis” is nothing more than making sense of information in a table. It consists of filtering, sorting, grouping, and manipulating data tables with basic algebra and statistics.
In fact, you don’t need experience to understand the basics. You have already worked with data extensively in your life, and “analysis” is nothing more than a fancy word for good sense and basic logic.
Over time, people have intuitively categorized the best logical practices for treating data. These categories are what we call today types , methods , and techniques .
This article provides a comprehensive list of types, methods, and techniques, and explains the difference between them.
For a practical intro to data analysis (including types, methods, & techniques), check out our Intro to Data Analysis eBook for free.
Descriptive, Diagnostic, Predictive, & Prescriptive Analysis
If you Google “types of data analysis,” the first few results will explore descriptive , diagnostic , predictive , and prescriptive analysis. Why? Because these names are easy to understand and are used a lot in “the real world.”
Descriptive analysis is an informational method, diagnostic analysis explains “why” a phenomenon occurs, predictive analysis seeks to forecast the result of an action, and prescriptive analysis identifies solutions to a specific problem.
That said, these are only four branches of a larger analytical tree.
Good data analysts know how to position these four types within other analytical methods and tactics, allowing them to leverage strengths and weaknesses in each to uproot the most valuable insights.
Let’s explore the full analytical tree to understand how to appropriately assess and apply these four traditional types.
Tree diagram of Data Analysis Types, Methods, and Techniques
Here’s a picture to visualize the structure and hierarchy of data analysis types, methods, and techniques.
If it’s too small you can view the picture in a new tab . Open it to follow along!

Note: basic descriptive statistics such as mean , median , and mode , as well as standard deviation , are not shown because most people are already familiar with them. In the diagram, they would fall under the “descriptive” analysis type.
Tree Diagram Explained
The highest-level classification of data analysis is quantitative vs qualitative . Quantitative implies numbers while qualitative implies information other than numbers.
Quantitative data analysis then splits into mathematical analysis and artificial intelligence (AI) analysis . Mathematical types then branch into descriptive , diagnostic , predictive , and prescriptive .
Methods falling under mathematical analysis include clustering , classification , forecasting , and optimization . Qualitative data analysis methods include content analysis , narrative analysis , discourse analysis , framework analysis , and/or grounded theory .
Moreover, mathematical techniques include regression , Nïave Bayes , Simple Exponential Smoothing , cohorts , factors , linear discriminants , and more, whereas techniques falling under the AI type include artificial neural networks , decision trees , evolutionary programming , and fuzzy logic . Techniques under qualitative analysis include text analysis , coding , idea pattern analysis , and word frequency .
It’s a lot to remember! Don’t worry, once you understand the relationship and motive behind all these terms, it’ll be like riding a bike.
We’ll move down the list from top to bottom and I encourage you to open the tree diagram above in a new tab so you can follow along .
But first, let’s just address the elephant in the room: what’s the difference between methods and techniques anyway?
Difference between methods and techniques
Though often used interchangeably, methods ands techniques are not the same. By definition, methods are the process by which techniques are applied, and techniques are the practical application of those methods.
For example, consider driving. Methods include staying in your lane, stopping at a red light, and parking in a spot. Techniques include turning the steering wheel, braking, and pushing the gas pedal.
Data sets: observations and fields
It’s important to understand the basic structure of data tables to comprehend the rest of the article. A data set consists of one far-left column containing observations, then a series of columns containing the fields (aka “traits” or “characteristics”) that describe each observations. For example, imagine we want a data table for fruit. It might look like this:
Now let’s turn to types, methods, and techniques. Each heading below consists of a description, relative importance, the nature of data it explores, and the motivation for using it.
Quantitative Analysis
- It accounts for more than 50% of all data analysis and is by far the most widespread and well-known type of data analysis.
- As you have seen, it holds descriptive, diagnostic, predictive, and prescriptive methods, which in turn hold some of the most important techniques available today, such as clustering and forecasting.
- It can be broken down into mathematical and AI analysis.
- Importance : Very high . Quantitative analysis is a must for anyone interesting in becoming or improving as a data analyst.
- Nature of Data: data treated under quantitative analysis is, quite simply, quantitative. It encompasses all numeric data.
- Motive: to extract insights. (Note: we’re at the top of the pyramid, this gets more insightful as we move down.)
Qualitative Analysis
- It accounts for less than 30% of all data analysis and is common in social sciences .
- It can refer to the simple recognition of qualitative elements, which is not analytic in any way, but most often refers to methods that assign numeric values to non-numeric data for analysis.
- Because of this, some argue that it’s ultimately a quantitative type.
- Importance: Medium. In general, knowing qualitative data analysis is not common or even necessary for corporate roles. However, for researchers working in social sciences, its importance is very high .
- Nature of Data: data treated under qualitative analysis is non-numeric. However, as part of the analysis, analysts turn non-numeric data into numbers, at which point many argue it is no longer qualitative analysis.
- Motive: to extract insights. (This will be more important as we move down the pyramid.)
Mathematical Analysis
- Description: mathematical data analysis is a subtype of qualitative data analysis that designates methods and techniques based on statistics, algebra, and logical reasoning to extract insights. It stands in opposition to artificial intelligence analysis.
- Importance: Very High. The most widespread methods and techniques fall under mathematical analysis. In fact, it’s so common that many people use “quantitative” and “mathematical” analysis interchangeably.
- Nature of Data: numeric. By definition, all data under mathematical analysis are numbers.
- Motive: to extract measurable insights that can be used to act upon.
Artificial Intelligence & Machine Learning Analysis
- Description: artificial intelligence and machine learning analyses designate techniques based on the titular skills. They are not traditionally mathematical, but they are quantitative since they use numbers. Applications of AI & ML analysis techniques are developing, but they’re not yet mainstream enough to show promise across the field.
- Importance: Medium . As of today (September 2020), you don’t need to be fluent in AI & ML data analysis to be a great analyst. BUT, if it’s a field that interests you, learn it. Many believe that in 10 year’s time its importance will be very high .
- Nature of Data: numeric.
- Motive: to create calculations that build on themselves in order and extract insights without direct input from a human.
Descriptive Analysis
- Description: descriptive analysis is a subtype of mathematical data analysis that uses methods and techniques to provide information about the size, dispersion, groupings, and behavior of data sets. This may sounds complicated, but just think about mean, median, and mode: all three are types of descriptive analysis. They provide information about the data set. We’ll look at specific techniques below.
- Importance: Very high. Descriptive analysis is among the most commonly used data analyses in both corporations and research today.
- Nature of Data: the nature of data under descriptive statistics is sets. A set is simply a collection of numbers that behaves in predictable ways. Data reflects real life, and there are patterns everywhere to be found. Descriptive analysis describes those patterns.
- Motive: the motive behind descriptive analysis is to understand how numbers in a set group together, how far apart they are from each other, and how often they occur. As with most statistical analysis, the more data points there are, the easier it is to describe the set.
Diagnostic Analysis
- Description: diagnostic analysis answers the question “why did it happen?” It is an advanced type of mathematical data analysis that manipulates multiple techniques, but does not own any single one. Analysts engage in diagnostic analysis when they try to explain why.
- Importance: Very high. Diagnostics are probably the most important type of data analysis for people who don’t do analysis because they’re valuable to anyone who’s curious. They’re most common in corporations, as managers often only want to know the “why.”
- Nature of Data : data under diagnostic analysis are data sets. These sets in themselves are not enough under diagnostic analysis. Instead, the analyst must know what’s behind the numbers in order to explain “why.” That’s what makes diagnostics so challenging yet so valuable.
- Motive: the motive behind diagnostics is to diagnose — to understand why.
Predictive Analysis
- Description: predictive analysis uses past data to project future data. It’s very often one of the first kinds of analysis new researchers and corporate analysts use because it is intuitive. It is a subtype of the mathematical type of data analysis, and its three notable techniques are regression, moving average, and exponential smoothing.
- Importance: Very high. Predictive analysis is critical for any data analyst working in a corporate environment. Companies always want to know what the future will hold — especially for their revenue.
- Nature of Data: Because past and future imply time, predictive data always includes an element of time. Whether it’s minutes, hours, days, months, or years, we call this time series data . In fact, this data is so important that I’ll mention it twice so you don’t forget: predictive analysis uses time series data .
- Motive: the motive for investigating time series data with predictive analysis is to predict the future in the most analytical way possible.
Prescriptive Analysis
- Description: prescriptive analysis is a subtype of mathematical analysis that answers the question “what will happen if we do X?” It’s largely underestimated in the data analysis world because it requires diagnostic and descriptive analyses to be done before it even starts. More than simple predictive analysis, prescriptive analysis builds entire data models to show how a simple change could impact the ensemble.
- Importance: High. Prescriptive analysis is most common under the finance function in many companies. Financial analysts use it to build a financial model of the financial statements that show how that data will change given alternative inputs.
- Nature of Data: the nature of data in prescriptive analysis is data sets. These data sets contain patterns that respond differently to various inputs. Data that is useful for prescriptive analysis contains correlations between different variables. It’s through these correlations that we establish patterns and prescribe action on this basis. This analysis cannot be performed on data that exists in a vacuum — it must be viewed on the backdrop of the tangibles behind it.
- Motive: the motive for prescriptive analysis is to establish, with an acceptable degree of certainty, what results we can expect given a certain action. As you might expect, this necessitates that the analyst or researcher be aware of the world behind the data, not just the data itself.
Clustering Method
- Description: the clustering method groups data points together based on their relativeness closeness to further explore and treat them based on these groupings. There are two ways to group clusters: intuitively and statistically (or K-means).
- Importance: Very high. Though most corporate roles group clusters intuitively based on management criteria, a solid understanding of how to group them mathematically is an excellent descriptive and diagnostic approach to allow for prescriptive analysis thereafter.
- Nature of Data : the nature of data useful for clustering is sets with 1 or more data fields. While most people are used to looking at only two dimensions (x and y), clustering becomes more accurate the more fields there are.
- Motive: the motive for clustering is to understand how data sets group and to explore them further based on those groups.
- Here’s an example set:

Classification Method
- Description: the classification method aims to separate and group data points based on common characteristics . This can be done intuitively or statistically.
- Importance: High. While simple on the surface, classification can become quite complex. It’s very valuable in corporate and research environments, but can feel like its not worth the work. A good analyst can execute it quickly to deliver results.
- Nature of Data: the nature of data useful for classification is data sets. As we will see, it can be used on qualitative data as well as quantitative. This method requires knowledge of the substance behind the data, not just the numbers themselves.
- Motive: the motive for classification is group data not based on mathematical relationships (which would be clustering), but by predetermined outputs. This is why it’s less useful for diagnostic analysis, and more useful for prescriptive analysis.
Forecasting Method
- Description: the forecasting method uses time past series data to forecast the future.
- Importance: Very high. Forecasting falls under predictive analysis and is arguably the most common and most important method in the corporate world. It is less useful in research, which prefers to understand the known rather than speculate about the future.
- Nature of Data: data useful for forecasting is time series data, which, as we’ve noted, always includes a variable of time.
- Motive: the motive for the forecasting method is the same as that of prescriptive analysis: the confidently estimate future values.
Optimization Method
- Description: the optimization method maximized or minimizes values in a set given a set of criteria. It is arguably most common in prescriptive analysis. In mathematical terms, it is maximizing or minimizing a function given certain constraints.
- Importance: Very high. The idea of optimization applies to more analysis types than any other method. In fact, some argue that it is the fundamental driver behind data analysis. You would use it everywhere in research and in a corporation.
- Nature of Data: the nature of optimizable data is a data set of at least two points.
- Motive: the motive behind optimization is to achieve the best result possible given certain conditions.
Content Analysis Method
- Description: content analysis is a method of qualitative analysis that quantifies textual data to track themes across a document. It’s most common in academic fields and in social sciences, where written content is the subject of inquiry.
- Importance: High. In a corporate setting, content analysis as such is less common. If anything Nïave Bayes (a technique we’ll look at below) is the closest corporations come to text. However, it is of the utmost importance for researchers. If you’re a researcher, check out this article on content analysis .
- Nature of Data: data useful for content analysis is textual data.
- Motive: the motive behind content analysis is to understand themes expressed in a large text
Narrative Analysis Method
- Description: narrative analysis is a method of qualitative analysis that quantifies stories to trace themes in them. It’s differs from content analysis because it focuses on stories rather than research documents, and the techniques used are slightly different from those in content analysis (very nuances and outside the scope of this article).
- Importance: Low. Unless you are highly specialized in working with stories, narrative analysis rare.
- Nature of Data: the nature of the data useful for the narrative analysis method is narrative text.
- Motive: the motive for narrative analysis is to uncover hidden patterns in narrative text.
Discourse Analysis Method
- Description: the discourse analysis method falls under qualitative analysis and uses thematic coding to trace patterns in real-life discourse. That said, real-life discourse is oral, so it must first be transcribed into text.
- Importance: Low. Unless you are focused on understand real-world idea sharing in a research setting, this kind of analysis is less common than the others on this list.
- Nature of Data: the nature of data useful in discourse analysis is first audio files, then transcriptions of those audio files.
- Motive: the motive behind discourse analysis is to trace patterns of real-world discussions. (As a spooky sidenote, have you ever felt like your phone microphone was listening to you and making reading suggestions? If it was, the method was discourse analysis.)
Framework Analysis Method
- Description: the framework analysis method falls under qualitative analysis and uses similar thematic coding techniques to content analysis. However, where content analysis aims to discover themes, framework analysis starts with a framework and only considers elements that fall in its purview.
- Importance: Low. As with the other textual analysis methods, framework analysis is less common in corporate settings. Even in the world of research, only some use it. Strangely, it’s very common for legislative and political research.
- Nature of Data: the nature of data useful for framework analysis is textual.
- Motive: the motive behind framework analysis is to understand what themes and parts of a text match your search criteria.
Grounded Theory Method
- Description: the grounded theory method falls under qualitative analysis and uses thematic coding to build theories around those themes.
- Importance: Low. Like other qualitative analysis techniques, grounded theory is less common in the corporate world. Even among researchers, you would be hard pressed to find many using it. Though powerful, it’s simply too rare to spend time learning.
- Nature of Data: the nature of data useful in the grounded theory method is textual.
- Motive: the motive of grounded theory method is to establish a series of theories based on themes uncovered from a text.
Clustering Technique: K-Means
- Description: k-means is a clustering technique in which data points are grouped in clusters that have the closest means. Though not considered AI or ML, it inherently requires the use of supervised learning to reevaluate clusters as data points are added. Clustering techniques can be used in diagnostic, descriptive, & prescriptive data analyses.
- Importance: Very important. If you only take 3 things from this article, k-means clustering should be part of it. It is useful in any situation where n observations have multiple characteristics and we want to put them in groups.
- Nature of Data: the nature of data is at least one characteristic per observation, but the more the merrier.
- Motive: the motive for clustering techniques such as k-means is to group observations together and either understand or react to them.
Regression Technique
- Description: simple and multivariable regressions use either one independent variable or combination of multiple independent variables to calculate a correlation to a single dependent variable using constants. Regressions are almost synonymous with correlation today.
- Importance: Very high. Along with clustering, if you only take 3 things from this article, regression techniques should be part of it. They’re everywhere in corporate and research fields alike.
- Nature of Data: the nature of data used is regressions is data sets with “n” number of observations and as many variables as are reasonable. It’s important, however, to distinguish between time series data and regression data. You cannot use regressions or time series data without accounting for time. The easier way is to use techniques under the forecasting method.
- Motive: The motive behind regression techniques is to understand correlations between independent variable(s) and a dependent one.
Nïave Bayes Technique
- Description: Nïave Bayes is a classification technique that uses simple probability to classify items based previous classifications. In plain English, the formula would be “the chance that thing with trait x belongs to class c depends on (=) the overall chance of trait x belonging to class c, multiplied by the overall chance of class c, divided by the overall chance of getting trait x.” As a formula, it’s P(c|x) = P(x|c) * P(c) / P(x).
- Importance: High. Nïave Bayes is a very common, simplistic classification techniques because it’s effective with large data sets and it can be applied to any instant in which there is a class. Google, for example, might use it to group webpages into groups for certain search engine queries.
- Nature of Data: the nature of data for Nïave Bayes is at least one class and at least two traits in a data set.
- Motive: the motive behind Nïave Bayes is to classify observations based on previous data. It’s thus considered part of predictive analysis.
Cohorts Technique
- Description: cohorts technique is a type of clustering method used in behavioral sciences to separate users by common traits. As with clustering, it can be done intuitively or mathematically, the latter of which would simply be k-means.
- Importance: Very high. With regard to resembles k-means, the cohort technique is more of a high-level counterpart. In fact, most people are familiar with it as a part of Google Analytics. It’s most common in marketing departments in corporations, rather than in research.
- Nature of Data: the nature of cohort data is data sets in which users are the observation and other fields are used as defining traits for each cohort.
- Motive: the motive for cohort analysis techniques is to group similar users and analyze how you retain them and how the churn.
Factor Technique
- Description: the factor analysis technique is a way of grouping many traits into a single factor to expedite analysis. For example, factors can be used as traits for Nïave Bayes classifications instead of more general fields.
- Importance: High. While not commonly employed in corporations, factor analysis is hugely valuable. Good data analysts use it to simplify their projects and communicate them more clearly.
- Nature of Data: the nature of data useful in factor analysis techniques is data sets with a large number of fields on its observations.
- Motive: the motive for using factor analysis techniques is to reduce the number of fields in order to more quickly analyze and communicate findings.
Linear Discriminants Technique
- Description: linear discriminant analysis techniques are similar to regressions in that they use one or more independent variable to determine a dependent variable; however, the linear discriminant technique falls under a classifier method since it uses traits as independent variables and class as a dependent variable. In this way, it becomes a classifying method AND a predictive method.
- Importance: High. Though the analyst world speaks of and uses linear discriminants less commonly, it’s a highly valuable technique to keep in mind as you progress in data analysis.
- Nature of Data: the nature of data useful for the linear discriminant technique is data sets with many fields.
- Motive: the motive for using linear discriminants is to classify observations that would be otherwise too complex for simple techniques like Nïave Bayes.
Exponential Smoothing Technique
- Description: exponential smoothing is a technique falling under the forecasting method that uses a smoothing factor on prior data in order to predict future values. It can be linear or adjusted for seasonality. The basic principle behind exponential smoothing is to use a percent weight (value between 0 and 1 called alpha) on more recent values in a series and a smaller percent weight on less recent values. The formula is f(x) = current period value * alpha + previous period value * 1-alpha.
- Importance: High. Most analysts still use the moving average technique (covered next) for forecasting, though it is less efficient than exponential moving, because it’s easy to understand. However, good analysts will have exponential smoothing techniques in their pocket to increase the value of their forecasts.
- Nature of Data: the nature of data useful for exponential smoothing is time series data . Time series data has time as part of its fields .
- Motive: the motive for exponential smoothing is to forecast future values with a smoothing variable.
Moving Average Technique
- Description: the moving average technique falls under the forecasting method and uses an average of recent values to predict future ones. For example, to predict rainfall in April, you would take the average of rainfall from January to March. It’s simple, yet highly effective.
- Importance: Very high. While I’m personally not a huge fan of moving averages due to their simplistic nature and lack of consideration for seasonality, they’re the most common forecasting technique and therefore very important.
- Nature of Data: the nature of data useful for moving averages is time series data .
- Motive: the motive for moving averages is to predict future values is a simple, easy-to-communicate way.
Neural Networks Technique
- Description: neural networks are a highly complex artificial intelligence technique that replicate a human’s neural analysis through a series of hyper-rapid computations and comparisons that evolve in real time. This technique is so complex that an analyst must use computer programs to perform it.
- Importance: Medium. While the potential for neural networks is theoretically unlimited, it’s still little understood and therefore uncommon. You do not need to know it by any means in order to be a data analyst.
- Nature of Data: the nature of data useful for neural networks is data sets of astronomical size, meaning with 100s of 1000s of fields and the same number of row at a minimum .
- Motive: the motive for neural networks is to understand wildly complex phenomenon and data to thereafter act on it.
Decision Tree Technique
- Description: the decision tree technique uses artificial intelligence algorithms to rapidly calculate possible decision pathways and their outcomes on a real-time basis. It’s so complex that computer programs are needed to perform it.
- Importance: Medium. As with neural networks, decision trees with AI are too little understood and are therefore uncommon in corporate and research settings alike.
- Nature of Data: the nature of data useful for the decision tree technique is hierarchical data sets that show multiple optional fields for each preceding field.
- Motive: the motive for decision tree techniques is to compute the optimal choices to make in order to achieve a desired result.
Evolutionary Programming Technique
- Description: the evolutionary programming technique uses a series of neural networks, sees how well each one fits a desired outcome, and selects only the best to test and retest. It’s called evolutionary because is resembles the process of natural selection by weeding out weaker options.
- Importance: Medium. As with the other AI techniques, evolutionary programming just isn’t well-understood enough to be usable in many cases. It’s complexity also makes it hard to explain in corporate settings and difficult to defend in research settings.
- Nature of Data: the nature of data in evolutionary programming is data sets of neural networks, or data sets of data sets.
- Motive: the motive for using evolutionary programming is similar to decision trees: understanding the best possible option from complex data.
- Video example :
Fuzzy Logic Technique
- Description: fuzzy logic is a type of computing based on “approximate truths” rather than simple truths such as “true” and “false.” It is essentially two tiers of classification. For example, to say whether “Apples are good,” you need to first classify that “Good is x, y, z.” Only then can you say apples are good. Another way to see it helping a computer see truth like humans do: “definitely true, probably true, maybe true, probably false, definitely false.”
- Importance: Medium. Like the other AI techniques, fuzzy logic is uncommon in both research and corporate settings, which means it’s less important in today’s world.
- Nature of Data: the nature of fuzzy logic data is huge data tables that include other huge data tables with a hierarchy including multiple subfields for each preceding field.
- Motive: the motive of fuzzy logic to replicate human truth valuations in a computer is to model human decisions based on past data. The obvious possible application is marketing.
Text Analysis Technique
- Description: text analysis techniques fall under the qualitative data analysis type and use text to extract insights.
- Importance: Medium. Text analysis techniques, like all the qualitative analysis type, are most valuable for researchers.
- Nature of Data: the nature of data useful in text analysis is words.
- Motive: the motive for text analysis is to trace themes in a text across sets of very long documents, such as books.
Coding Technique
- Description: the coding technique is used in textual analysis to turn ideas into uniform phrases and analyze the number of times and the ways in which those ideas appear. For this reason, some consider it a quantitative technique as well. You can learn more about coding and the other qualitative techniques here .
- Importance: Very high. If you’re a researcher working in social sciences, coding is THE analysis techniques, and for good reason. It’s a great way to add rigor to analysis. That said, it’s less common in corporate settings.
- Nature of Data: the nature of data useful for coding is long text documents.
- Motive: the motive for coding is to make tracing ideas on paper more than an exercise of the mind by quantifying it and understanding is through descriptive methods.
Idea Pattern Technique
- Description: the idea pattern analysis technique fits into coding as the second step of the process. Once themes and ideas are coded, simple descriptive analysis tests may be run. Some people even cluster the ideas!
- Importance: Very high. If you’re a researcher, idea pattern analysis is as important as the coding itself.
- Nature of Data: the nature of data useful for idea pattern analysis is already coded themes.
- Motive: the motive for the idea pattern technique is to trace ideas in otherwise unmanageably-large documents.
Word Frequency Technique
- Description: word frequency is a qualitative technique that stands in opposition to coding and uses an inductive approach to locate specific words in a document in order to understand its relevance. Word frequency is essentially the descriptive analysis of qualitative data because it uses stats like mean, median, and mode to gather insights.
- Importance: High. As with the other qualitative approaches, word frequency is very important in social science research, but less so in corporate settings.
- Nature of Data: the nature of data useful for word frequency is long, informative documents.
- Motive: the motive for word frequency is to locate target words to determine the relevance of a document in question.
Types of data analysis in research
Types of data analysis in research methodology include every item discussed in this article. As a list, they are:
- Quantitative
- Qualitative
- Mathematical
- Machine Learning and AI
- Descriptive
- Prescriptive
- Classification
- Forecasting
- Optimization
- Grounded theory
- Artificial Neural Networks
- Decision Trees
- Evolutionary Programming
- Fuzzy Logic
- Text analysis
- Idea Pattern Analysis
- Word Frequency Analysis
- Nïave Bayes
- Exponential smoothing
- Moving average
- Linear discriminant
Types of data analysis in qualitative research
As a list, the types of data analysis in qualitative research are the following methods:
Types of data analysis in quantitative research
As a list, the types of data analysis in quantitative research are:
Data analysis methods
As a list, data analysis methods are:
- Content (qualitative)
- Narrative (qualitative)
- Discourse (qualitative)
- Framework (qualitative)
- Grounded theory (qualitative)
Quantitative data analysis methods
As a list, quantitative data analysis methods are:
Tabular View of Data Analysis Types, Methods, and Techniques
About the author.
Noah is the founder & Editor-in-Chief at AnalystAnswers. He is a transatlantic professional and entrepreneur with 5+ years of corporate finance and data analytics experience, as well as 3+ years in consumer financial products and business software. He started AnalystAnswers to provide aspiring professionals with accessible explanations of otherwise dense finance and data concepts. Noah believes everyone can benefit from an analytical mindset in growing digital world. When he's not busy at work, Noah likes to explore new European cities, exercise, and spend time with friends and family.
File available immediately.

Notice: JavaScript is required for this content.

Quantitative Data Analysis: Types, Analysis & Examples

Varun Saharawat is a seasoned professional in the fields of SEO and content writing. With a profound knowledge of the intricate aspects of these disciplines, Varun has established himself as a valuable asset in the world of digital marketing and online content creation.
Analysis of Quantitative data enables you to transform raw data points, typically organised in spreadsheets, into actionable insights. Refer to the article to know more!

Analysis of Quantitative Data : Data, data everywhere — it’s impossible to escape it in today’s digitally connected world. With business and personal activities leaving digital footprints, vast amounts of quantitative data are being generated every second of every day. While data on its own may seem impersonal and cold, in the right hands it can be transformed into valuable insights that drive meaningful decision-making. In this article, we will discuss analysis of quantitative data types and examples!
If you are looking to acquire hands-on experience in quantitative data analysis, look no further than Physics Wallah’s Data Analytics Course . And as a token of appreciation for reading this blog post until the end, use our exclusive coupon code “READER” to get a discount on the course fee.
Table of Contents
What is the Quantitative Analysis Method?
Quantitative Analysis refers to a mathematical approach that gathers and evaluates measurable and verifiable data. This method is utilized to assess performance and various aspects of a business or research. It involves the use of mathematical and statistical techniques to analyze data. Quantitative methods emphasize objective measurements, focusing on statistical, analytical, or numerical analysis of data. It collects data and studies it to derive insights or conclusions.
In a business context, it helps in evaluating the performance and efficiency of operations. Quantitative analysis can be applied across various domains, including finance, research, and chemistry, where data can be converted into numbers for analysis.
Also Read: Analysis vs. Analytics: How Are They Different?
What is the Best Analysis for Quantitative Data?
The “best” analysis for quantitative data largely depends on the specific research objectives, the nature of the data collected, the research questions posed, and the context in which the analysis is conducted. Quantitative data analysis encompasses a wide range of techniques, each suited for different purposes. Here are some commonly employed methods, along with scenarios where they might be considered most appropriate:
1) Descriptive Statistics:
- When to Use: To summarize and describe the basic features of the dataset, providing simple summaries about the sample and measures of central tendency and variability.
- Example: Calculating means, medians, standard deviations, and ranges to describe a dataset.
2) Inferential Statistics:
- When to Use: When you want to make predictions or inferences about a population based on a sample, testing hypotheses, or determining relationships between variables.
- Example: Conducting t-tests to compare means between two groups or performing regression analysis to understand the relationship between an independent variable and a dependent variable.
3) Correlation and Regression Analysis:
- When to Use: To examine relationships between variables, determining the strength and direction of associations, or predicting one variable based on another.
- Example: Assessing the correlation between customer satisfaction scores and sales revenue or predicting house prices based on variables like location, size, and amenities.
4) Factor Analysis:
- When to Use: When dealing with a large set of variables and aiming to identify underlying relationships or latent factors that explain patterns of correlations within the data.
- Example: Exploring underlying constructs influencing employee engagement using survey responses across multiple indicators.
5) Time Series Analysis:
- When to Use: When analyzing data points collected or recorded at successive time intervals to identify patterns, trends, seasonality, or forecast future values.
- Example: Analyzing monthly sales data over several years to detect seasonal trends or forecasting stock prices based on historical data patterns.
6) Cluster Analysis:
- When to Use: To segment a dataset into distinct groups or clusters based on similarities, enabling pattern recognition, customer segmentation, or data reduction.
- Example: Segmenting customers into distinct groups based on purchasing behavior, demographic factors, or preferences.
The “best” analysis for quantitative data is not one-size-fits-all but rather depends on the research objectives, hypotheses, data characteristics, and contextual factors. Often, a combination of analytical techniques may be employed to derive comprehensive insights and address multifaceted research questions effectively. Therefore, selecting the appropriate analysis requires careful consideration of the research goals, methodological rigor, and interpretative relevance to ensure valid, reliable, and actionable outcomes.
Analysis of Quantitative Data in Quantitative Research
Analyzing quantitative data in quantitative research involves a systematic process of examining numerical information to uncover patterns, relationships, and insights that address specific research questions or objectives. Here’s a structured overview of the analysis process:
1) Data Preparation:
- Data Cleaning: Identify and address errors, inconsistencies, missing values, and outliers in the dataset to ensure its integrity and reliability.
- Variable Transformation: Convert variables into appropriate formats or scales, if necessary, for analysis (e.g., normalization, standardization).
2) Descriptive Statistics:
- Central Tendency: Calculate measures like mean, median, and mode to describe the central position of the data.
- Variability: Assess the spread or dispersion of data using measures such as range, variance, standard deviation, and interquartile range.
- Frequency Distribution: Create tables, histograms, or bar charts to display the distribution of values for categorical or discrete variables.
3) Exploratory Data Analysis (EDA):
- Data Visualization: Generate graphical representations like scatter plots, box plots, histograms, or heatmaps to visualize relationships, distributions, and patterns in the data.
- Correlation Analysis: Examine the strength and direction of relationships between variables using correlation coefficients.
4) Inferential Statistics:
- Hypothesis Testing: Formulate null and alternative hypotheses based on research questions, selecting appropriate statistical tests (e.g., t-tests, ANOVA, chi-square tests) to assess differences, associations, or effects.
- Confidence Intervals: Estimate population parameters using sample statistics and determine the range within which the true parameter is likely to fall.
5) Regression Analysis:
- Linear Regression: Identify and quantify relationships between an outcome variable and one or more predictor variables, assessing the strength, direction, and significance of associations.
- Multiple Regression: Evaluate the combined effect of multiple independent variables on a dependent variable, controlling for confounding factors.
6) Factor Analysis and Structural Equation Modeling:
- Factor Analysis: Identify underlying dimensions or constructs that explain patterns of correlations among observed variables, reducing data complexity.
- Structural Equation Modeling (SEM): Examine complex relationships between observed and latent variables, assessing direct and indirect effects within a hypothesized model.
7) Time Series Analysis and Forecasting:
- Trend Analysis: Analyze patterns, trends, and seasonality in time-ordered data to understand historical patterns and predict future values.
- Forecasting Models: Develop predictive models (e.g., ARIMA, exponential smoothing) to anticipate future trends, demand, or outcomes based on historical data patterns.
8) Interpretation and Reporting:
- Interpret Results: Translate statistical findings into meaningful insights, discussing implications, limitations, and conclusions in the context of the research objectives.
- Documentation: Document the analysis process, methodologies, assumptions, and findings systematically for transparency, reproducibility, and peer review.
Also Read: Learning Path to Become a Data Analyst in 2024
Analysis of Quantitative Data Examples
Analyzing quantitative data involves various statistical methods and techniques to derive meaningful insights from numerical data. Here are some examples illustrating the analysis of quantitative data across different contexts:
How to Write Data Analysis in Quantitative Research Proposal?
Writing the data analysis section in a quantitative research proposal requires careful planning and organization to convey a clear, concise, and methodologically sound approach to analyzing the collected data. Here’s a step-by-step guide on how to write the data analysis section effectively:
Step 1: Begin with an Introduction
- Contextualize : Briefly reintroduce the research objectives, questions, and the significance of the study.
- Purpose Statement : Clearly state the purpose of the data analysis section, outlining what readers can expect in this part of the proposal.
Step 2: Describe Data Collection Methods
- Detail Collection Techniques : Provide a concise overview of the methods used for data collection (e.g., surveys, experiments, observations).
- Instrumentation : Mention any tools, instruments, or software employed for data gathering and its relevance.
Step 3 : Discuss Data Cleaning Procedures
- Data Cleaning : Describe the procedures for cleaning and pre-processing the data.
- Handling Outliers & Missing Data : Explain how outliers, missing values, and other inconsistencies will be managed to ensure data quality.
Step 4 : Present Analytical Techniques
- Descriptive Statistics : Outline the descriptive statistics that will be calculated to summarize the data (e.g., mean, median, mode, standard deviation).
- Inferential Statistics : Specify the inferential statistical tests or models planned for deeper analysis (e.g., t-tests, ANOVA, regression).
Step 5: State Hypotheses & Testing Procedures
- Hypothesis Formulation : Clearly state the null and alternative hypotheses based on the research questions or objectives.
- Testing Strategy : Detail the procedures for hypothesis testing, including the chosen significance level (e.g., α = 0.05) and statistical criteria.
Step 6 : Provide a Sample Analysis Plan
- Step-by-Step Plan : Offer a sample plan detailing the sequence of steps involved in the data analysis process.
- Software & Tools : Mention any specific statistical software or tools that will be utilized for analysis.
Step 7 : Address Validity & Reliability
- Validity : Discuss how you will ensure the validity of the data analysis methods and results.
- Reliability : Explain measures taken to enhance the reliability and replicability of the study findings.
Step 8 : Discuss Ethical Considerations
- Ethical Compliance : Address ethical considerations related to data privacy, confidentiality, and informed consent.
- Compliance with Guidelines : Ensure that your data analysis methods align with ethical guidelines and institutional policies.
Step 9 : Acknowledge Limitations
- Limitations : Acknowledge potential limitations in the data analysis methods or data set.
- Mitigation Strategies : Offer strategies or alternative approaches to mitigate identified limitations.
Step 10 : Conclude the Section
- Summary : Summarize the key points discussed in the data analysis section.
- Transition : Provide a smooth transition to subsequent sections of the research proposal, such as the conclusion or references.
Step 11 : Proofread & Revise
- Review : Carefully review the data analysis section for clarity, coherence, and consistency.
- Feedback : Seek feedback from peers, advisors, or mentors to refine your approach and ensure methodological rigor.
What are the 4 Types of Quantitative Analysis?
Quantitative analysis encompasses various methods to evaluate and interpret numerical data. While the specific categorization can vary based on context, here are four broad types of quantitative analysis commonly recognized:
- Descriptive Analysis: This involves summarizing and presenting data to describe its main features, such as mean, median, mode, standard deviation, and range. Descriptive statistics provide a straightforward overview of the dataset’s characteristics.
- Inferential Analysis: This type of analysis uses sample data to make predictions or inferences about a larger population. Techniques like hypothesis testing, regression analysis, and confidence intervals fall under this category. The goal is to draw conclusions that extend beyond the immediate data collected.
- Time-Series Analysis: In this method, data points are collected, recorded, and analyzed over successive time intervals. Time-series analysis helps identify patterns, trends, and seasonal variations within the data. It’s particularly useful in forecasting future values based on historical trends.
- Causal or Experimental Research: This involves establishing a cause-and-effect relationship between variables. Through experimental designs, researchers manipulate one variable to observe the effect on another variable while controlling for external factors. Randomized controlled trials are a common method within this type of quantitative analysis.
Each type of quantitative analysis serves specific purposes and is applied based on the nature of the data and the research objectives.
Also Read: AI and Predictive Analytics: Examples, Tools, Uses, Ai Vs Predictive Analytics
Steps to Effective Quantitative Data Analysis
Quantitative data analysis need not be daunting; it’s a systematic process that anyone can master. To harness actionable insights from your company’s data, follow these structured steps:
Step 1 : Gather Data Strategically
Initiating the analysis journey requires a foundation of relevant data. Employ quantitative research methods to accumulate numerical insights from diverse channels such as:
- Interviews or Focus Groups: Engage directly with stakeholders or customers to gather specific numerical feedback.
- Digital Analytics: Utilize tools like Google Analytics to extract metrics related to website traffic, user behavior, and conversions.
- Observational Tools: Leverage heatmaps, click-through rates, or session recordings to capture user interactions and preferences.
- Structured Questionnaires: Deploy surveys or feedback mechanisms that employ close-ended questions for precise responses.
Ensure that your data collection methods align with your research objectives, focusing on granularity and accuracy.
Step 2 : Refine and Cleanse Your Data
Raw data often comes with imperfections. Scrutinize your dataset to identify and rectify:
- Errors and Inconsistencies: Address any inaccuracies or discrepancies that could mislead your analysis.
- Duplicates: Eliminate repeated data points that can skew results.
- Outliers: Identify and assess outliers, determining whether they should be adjusted or excluded based on contextual relevance.
Cleaning your dataset ensures that subsequent analyses are based on reliable and consistent information, enhancing the credibility of your findings.
Step 3 : Delve into Analysis with Precision
With a refined dataset at your disposal, transition into the analytical phase. Employ both descriptive and inferential analysis techniques:
- Descriptive Analysis: Summarize key attributes of your dataset, computing metrics like averages, distributions, and frequencies.
- Inferential Analysis: Leverage statistical methodologies to derive insights, explore relationships between variables, or formulate predictions.
The objective is not just number crunching but deriving actionable insights. Interpret your findings to discern underlying patterns, correlations, or trends that inform strategic decision-making. For instance, if data indicates a notable relationship between user engagement metrics and specific website features, consider optimizing those features for enhanced user experience.
Step 4 : Visual Representation and Communication
Transforming your analytical outcomes into comprehensible narratives is crucial for organizational alignment and decision-making. Leverage visualization tools and techniques to:
- Craft Engaging Visuals: Develop charts, graphs, or dashboards that encapsulate key findings and insights.
- Highlight Insights: Use visual elements to emphasize critical data points, trends, or comparative metrics effectively.
- Facilitate Stakeholder Engagement: Share your visual representations with relevant stakeholders, ensuring clarity and fostering informed discussions.
Tools like Tableau, Power BI, or specialized platforms like Hotjar can simplify the visualization process, enabling seamless representation and dissemination of your quantitative insights.
Also Read: Top 10 Must Use AI Tools for Data Analysis [2024 Edition]
Statistical Analysis in Quantitative Research
Statistical analysis is a cornerstone of quantitative research, providing the tools and techniques to interpret numerical data systematically. By applying statistical methods, researchers can identify patterns, relationships, and trends within datasets, enabling evidence-based conclusions and informed decision-making. Here’s an overview of the key aspects and methodologies involved in statistical analysis within quantitative research:
- Mean, Median, Mode: Measures of central tendency that summarize the average, middle, and most frequent values in a dataset, respectively.
- Standard Deviation, Variance: Indicators of data dispersion or variability around the mean.
- Frequency Distributions: Tabular or graphical representations that display the distribution of data values or categories.
- Hypothesis Testing: Formal methodologies to test hypotheses or assumptions about population parameters using sample data. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis.
- Confidence Intervals: Estimation techniques that provide a range of values within which a population parameter is likely to lie, based on sample data.
- Correlation and Regression Analysis: Techniques to explore relationships between variables, determining the strength and direction of associations. Regression analysis further enables prediction and modeling based on observed data patterns.
3) Probability Distributions:
- Normal Distribution: A bell-shaped distribution often observed in naturally occurring phenomena, forming the basis for many statistical tests.
- Binomial, Poisson, and Exponential Distributions: Specific probability distributions applicable to discrete or continuous random variables, depending on the nature of the research data.
4) Multivariate Analysis:
- Factor Analysis: A technique to identify underlying relationships between observed variables, often used in survey research or data reduction scenarios.
- Cluster Analysis: Methodologies that group similar objects or individuals based on predefined criteria, enabling segmentation or pattern recognition within datasets.
- Multivariate Regression: Extending regression analysis to multiple independent variables, assessing their collective impact on a dependent variable.
5) Data Modeling and Forecasting:
- Time Series Analysis: Analyzing data points collected or recorded at specific time intervals to identify patterns, trends, or seasonality.
- Predictive Analytics : Leveraging statistical models and machine learning algorithms to forecast future trends, outcomes, or behaviors based on historical data.
If this blog post has piqued your interest in the field of data analytics, then we highly recommend checking out Physics Wallah’s Data Analytics Course . This course covers all the fundamental concepts of quantitative data analysis and provides hands-on training for various tools and software used in the industry.
With a team of experienced instructors from different backgrounds and industries, you will gain a comprehensive understanding of a wide range of topics related to data analytics. And as an added bonus for being one of our dedicated readers, use the coupon code “ READER ” to get an exclusive discount on this course!
For Latest Tech Related Information, Join Our Official Free Telegram Group : PW Skills Telegram Group
Analysis of Quantitative Data FAQs
What is quantitative data analysis.
Quantitative data analysis involves the systematic process of collecting, cleaning, interpreting, and presenting numerical data to identify patterns, trends, and relationships through statistical methods and mathematical calculations.
What are the main steps involved in quantitative data analysis?
The primary steps include data collection, data cleaning, statistical analysis (descriptive and inferential), interpretation of results, and visualization of findings using graphs or charts.
What is the difference between descriptive and inferential analysis?
Descriptive analysis summarizes and describes the main aspects of the dataset (e.g., mean, median, mode), while inferential analysis draws conclusions or predictions about a population based on a sample, using statistical tests and models.
How do I handle outliers in my quantitative data?
Outliers can be managed by identifying them through statistical methods, understanding their nature (error or valid data), and deciding whether to remove them, transform them, or conduct separate analyses to understand their impact.
Which statistical tests should I use for my quantitative research?
The choice of statistical tests depends on your research design, data type, and research questions. Common tests include t-tests, ANOVA, regression analysis, chi-square tests, and correlation analysis, among others.
- Top 10 Data Analytics Courses

Top 10 Best Data Analytics Courses to boost your career in 2025. Explore top online programs, certifications, and resources to…
- Business Intelligence Programs – Top 15 Business Intelligence Tools in 2025

Business Intelligence Programs empower organizations to transform data into actionable insights, enhancing decision-making and driving operational efficiency. Checkout the Top…
- What is Statistical Modeling? Definition and FAQs

Statistical Modeling states scover the definition, key concepts, and frequently asked questions about statistical modeling, including its applications in data…

Related Articles
- What is Diagnostic Analytics? Why it is Important
- Data Analyst Recruitment For Fresher By S&P Global, Apply Now!
- Cluster Analysis – Methods, Applications, and Algorithms
- Top 5 Data Analytics Jobs For Freshers In October
- 5 Examples Of Descriptive Analytics
- What Is Retail Analytics? The Ultimate Guide
- What Is Lexical Analysis? Explore In Detail

8 Types of Data Analysis
The different types of data analysis include descriptive, diagnostic, exploratory, inferential, predictive, causal, mechanistic and prescriptive. Here’s what you need to know about each one.
Data analysis is an aspect of data science and data analytics that is all about analyzing data for different kinds of purposes. The data analysis process involves inspecting, cleaning, transforming and modeling data to draw useful insights from it.
Types of Data Analysis
- Descriptive analysis
- Diagnostic analysis
- Exploratory analysis
- Inferential analysis
- Predictive analysis
- Causal analysis
- Mechanistic analysis
- Prescriptive analysis
With its multiple facets, methodologies and techniques, data analysis is used in a variety of fields, including energy, healthcare and marketing, among others. As businesses thrive under the influence of technological advancements in data analytics, data analysis plays a huge role in decision-making , providing a better, faster and more effective system that minimizes risks and reduces human biases .
That said, there are different kinds of data analysis with different goals. We’ll examine each one below.
Two Camps of Data Analysis
Data analysis can be divided into two camps, according to the book R for Data Science :
- Hypothesis Generation: This involves looking deeply at the data and combining your domain knowledge to generate hypotheses about why the data behaves the way it does.
- Hypothesis Confirmation: This involves using a precise mathematical model to generate falsifiable predictions with statistical sophistication to confirm your prior hypotheses.
More on Data Analysis: Data Analyst vs. Data Scientist: Similarities and Differences Explained
Data analysis can be separated and organized into types, arranged in an increasing order of complexity.
1. Descriptive Analysis
The goal of descriptive analysis is to describe or summarize a set of data . Here’s what you need to know:
- Descriptive analysis is the very first analysis performed in the data analysis process.
- It generates simple summaries of samples and measurements.
- It involves common, descriptive statistics like measures of central tendency, variability, frequency and position.
Descriptive Analysis Example
Take the Covid-19 statistics page on Google, for example. The line graph is a pure summary of the cases/deaths, a presentation and description of the population of a particular country infected by the virus.
Descriptive analysis is the first step in analysis where you summarize and describe the data you have using descriptive statistics, and the result is a simple presentation of your data.
2. Diagnostic Analysis
Diagnostic analysis seeks to answer the question “Why did this happen?” by taking a more in-depth look at data to uncover subtle patterns. Here’s what you need to know:
- Diagnostic analysis typically comes after descriptive analysis, taking initial findings and investigating why certain patterns in data happen.
- Diagnostic analysis may involve analyzing other related data sources, including past data, to reveal more insights into current data trends.
- Diagnostic analysis is ideal for further exploring patterns in data to explain anomalies .
Diagnostic Analysis Example
A footwear store wants to review its website traffic levels over the previous 12 months. Upon compiling and assessing the data, the company’s marketing team finds that June experienced above-average levels of traffic while July and August witnessed slightly lower levels of traffic.
To find out why this difference occurred, the marketing team takes a deeper look. Team members break down the data to focus on specific categories of footwear. In the month of June, they discovered that pages featuring sandals and other beach-related footwear received a high number of views while these numbers dropped in July and August.
Marketers may also review other factors like seasonal changes and company sales events to see if other variables could have contributed to this trend.
3. Exploratory Analysis (EDA)
Exploratory analysis involves examining or exploring data and finding relationships between variables that were previously unknown. Here’s what you need to know:
- EDA helps you discover relationships between measures in your data, which are not evidence for the existence of the correlation, as denoted by the phrase, “ Correlation doesn’t imply causation .”
- It’s useful for discovering new connections and forming hypotheses. It drives design planning and data collection .
Exploratory Analysis Example
Climate change is an increasingly important topic as the global temperature has gradually risen over the years. One example of an exploratory data analysis on climate change involves taking the rise in temperature over the years from 1950 to 2020 and the increase of human activities and industrialization to find relationships from the data. For example, you may increase the number of factories, cars on the road and airplane flights to see how that correlates with the rise in temperature.
Exploratory analysis explores data to find relationships between measures without identifying the cause. It’s most useful when formulating hypotheses.
4. Inferential Analysis
Inferential analysis involves using a small sample of data to infer information about a larger population of data.
The goal of statistical modeling itself is all about using a small amount of information to extrapolate and generalize information to a larger group. Here’s what you need to know:
- Inferential analysis involves using estimated data that is representative of a population and gives a measure of uncertainty or standard deviation to your estimation.
- The accuracy of inference depends heavily on your sampling scheme. If the sample isn’t representative of the population, the generalization will be inaccurate. This is known as the central limit theorem .
Inferential Analysis Example
A psychological study on the benefits of sleep might have a total of 500 people involved. When they followed up with the candidates, the candidates reported to have better overall attention spans and well-being with seven to nine hours of sleep, while those with less sleep and more sleep than the given range suffered from reduced attention spans and energy. This study drawn from 500 people was just a tiny portion of the 7 billion people in the world, and is thus an inference of the larger population.
Inferential analysis extrapolates and generalizes the information of the larger group with a smaller sample to generate analysis and predictions.
5. Predictive Analysis
Predictive analysis involves using historical or current data to find patterns and make predictions about the future. Here’s what you need to know:
- The accuracy of the predictions depends on the input variables.
- Accuracy also depends on the types of models. A linear model might work well in some cases, and in other cases it might not.
- Using a variable to predict another one doesn’t denote a causal relationship.
Predictive Analysis Example
The 2020 United States election is a popular topic and many prediction models are built to predict the winning candidate. FiveThirtyEight did this to forecast the 2016 and 2020 elections. Prediction analysis for an election would require input variables such as historical polling data, trends and current polling data in order to return a good prediction. Something as large as an election wouldn’t just be using a linear model, but a complex model with certain tunings to best serve its purpose.
6. Causal Analysis
Causal analysis looks at the cause and effect of relationships between variables and is focused on finding the cause of a correlation. This way, researchers can examine how a change in one variable affects another. Here’s what you need to know:
- To find the cause, you have to question whether the observed correlations driving your conclusion are valid. Just looking at the surface data won’t help you discover the hidden mechanisms underlying the correlations.
- Causal analysis is applied in randomized studies focused on identifying causation.
- Causal analysis is the gold standard in data analysis and scientific studies where the cause of a phenomenon is to be extracted and singled out, like separating wheat from chaff.
- Good data is hard to find and requires expensive research and studies. These studies are analyzed in aggregate (multiple groups), and the observed relationships are just average effects (mean) of the whole population. This means the results might not apply to everyone.
Causal Analysis Example
Say you want to test out whether a new drug improves human strength and focus. To do that, you perform randomized control trials for the drug to test its effect. You compare the sample of candidates for your new drug against the candidates receiving a mock control drug through a few tests focused on strength and overall focus and attention. This will allow you to observe how the drug affects the outcome.
7. Mechanistic Analysis
Mechanistic analysis is used to understand exact changes in variables that lead to other changes in other variables . In some ways, it is a predictive analysis, but it’s modified to tackle studies that require high precision and meticulous methodologies for physical or engineering science. Here’s what you need to know:
- It’s applied in physical or engineering sciences, situations that require high precision and little room for error, only noise in data is measurement error.
- It’s designed to understand a biological or behavioral process, the pathophysiology of a disease or the mechanism of action of an intervention.
Mechanistic Analysis Example
Say an experiment is done to simulate safe and effective nuclear fusion to power the world. A mechanistic analysis of the study would entail a precise balance of controlling and manipulating variables with highly accurate measures of both variables and the desired outcomes. It’s this intricate and meticulous modus operandi toward these big topics that allows for scientific breakthroughs and advancement of society.
8. Prescriptive Analysis
Prescriptive analysis compiles insights from other previous data analyses and determines actions that teams or companies can take to prepare for predicted trends. Here’s what you need to know:
- Prescriptive analysis may come right after predictive analysis, but it may involve combining many different data analyses.
- Companies need advanced technology and plenty of resources to conduct prescriptive analysis. Artificial intelligence systems that process data and adjust automated tasks are an example of the technology required to perform prescriptive analysis.
Prescriptive Analysis Example
Prescriptive analysis is pervasive in everyday life, driving the curated content users consume on social media. On platforms like TikTok and Instagram, algorithms can apply prescriptive analysis to review past content a user has engaged with and the kinds of behaviors they exhibited with specific posts. Based on these factors, an algorithm seeks out similar content that is likely to elicit the same response and recommends it on a user’s personal feed.
More on Data Explaining the Empirical Rule for Normal Distribution
When to Use the Different Types of Data Analysis
- Descriptive analysis summarizes the data at hand and presents your data in a comprehensible way.
- Diagnostic analysis takes a more detailed look at data to reveal why certain patterns occur, making it a good method for explaining anomalies.
- Exploratory data analysis helps you discover correlations and relationships between variables in your data.
- Inferential analysis is for generalizing the larger population with a smaller sample size of data.
- Predictive analysis helps you make predictions about the future with data.
- Causal analysis emphasizes finding the cause of a correlation between variables.
- Mechanistic analysis is for measuring the exact changes in variables that lead to other changes in other variables.
- Prescriptive analysis combines insights from different data analyses to develop a course of action teams and companies can take to capitalize on predicted outcomes.
A few important tips to remember about data analysis include:
- Correlation doesn’t imply causation.
- EDA helps discover new connections and form hypotheses.
- Accuracy of inference depends on the sampling scheme.
- A good prediction depends on the right input variables.
- A simple linear model with enough data usually does the trick.
- Using a variable to predict another doesn’t denote causal relationships.
- Good data is hard to find, and to produce it requires expensive research.
- Results from studies are done in aggregate and are average effects and might not apply to everyone.
Frequently Asked Questions
What is an example of data analysis.
A marketing team reviews a company’s web traffic over the past 12 months. To understand why sales rise and fall during certain months, the team breaks down the data to look at shoe type, seasonal patterns and sales events. Based on this in-depth analysis, the team can determine variables that influenced web traffic and make adjustments as needed.
How do you know which data analysis method to use?
Selecting a data analysis method depends on the goals of the analysis and the complexity of the task, among other factors. It’s best to assess the circumstances and consider the pros and cons of each type of data analysis before moving forward with a particular method.
Recent Data Science Articles

- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

What is data analysis in research?
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Why analyze data in research?
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Types of data in research
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data : It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Finding patterns in the qualitative data
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
Methods used for data analysis in qualitative research
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
Choosing the right software can be tough. Whether you’re a researcher, business leader, or marketer, check out the top 10 qualitative data analysis software for analyzing qualitative data.
Data analysis in quantitative research
Preparing data for analysis.
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
Methods used for data analysis in quantitative research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
Considerations in research data analysis
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

Maximize Employee Feedback with QuestionPro Workforce’s Slack Integration
Nov 6, 2024

2024 Presidential Election Polls: Harris vs. Trump
Nov 5, 2024

Your First Question Should Be Anything But, “Is The Car Okay?” — Tuesday CX Thoughts

QuestionPro vs. Qualtrics: Who Offers the Best 360-Degree Feedback Platform for Your Needs?
Nov 4, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence
Part II: Data Analysis Methods in Quantitative Research
Data analysis methods in quantitative research.
We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim). Now, we are going to delve into two main statistical analyses to describe our data and make inferences about our data:
Descriptive Statistics and Inferential Statistics.
Descriptive Statistics:
Before you panic, we will not be going into statistical analyses very deeply. We want to simply get a good overview of some of the types of general statistical analyses so that it makes some sense to us when we read results in published research articles.
Descriptive statistics summarize or describe the characteristics of a data set. This is a method of simply organizing and describing our data. Why? Because data that are not organized in some fashion are super difficult to interpret.
Let’s say our sample is golden retrievers (population “canines”). Our descriptive statistics tell us more about the same.
- 37% of our sample is male, 43% female
- The mean age is 4 years
- Mode is 6 years
- Median age is 5.5 years

Let’s explore some of the types of descriptive statistics.
Frequency Distributions : A frequency distribution describes the number of observations for each possible value of a measured variable. The numbers are arranged from lowest to highest and features a count of how many times each value occurred.
For example, if 18 students have pet dogs, dog ownership has a frequency of 18.
We might see what other types of pets that students have. Maybe cats, fish, and hamsters. We find that 2 students have hamsters, 9 have fish, 1 has a cat.
You can see that it is very difficult to interpret the various pets into any meaningful interpretation, yes?
Now, let’s take those same pets and place them in a frequency distribution table.
As we can now see, this is much easier to interpret.
Let’s say that we want to know how many books our sample population of students have read in the last year. We collect our data and find this:
We can then take that table and plot it out on a frequency distribution graph. This makes it much easier to see how the numbers are disbursed. Easier on the eyes, yes?

Here’s another example of symmetrical, positive skew, and negative skew:

Correlation : Relationships between two research variables are called correlations . Remember, correlation is not cause-and-effect. Correlations simply measure the extent of relationship between two variables. To measure correlation in descriptive statistics, the statistical analysis called Pearson’s correlation coefficient I is often used. You do not need to know how to calculate this for this course. But, do remember that analysis test because you will often see this in published research articles. There really are no set guidelines on what measurement constitutes a “strong” or “weak” correlation, as it really depends on the variables being measured.
However, possible values for correlation coefficients range from -1.00 through .00 to +1.00. A value of +1 means that the two variables are positively correlated, as one variable goes up, the other goes up. A value of r = 0 means that the two variables are not linearly related.
Often, the data will be presented on a scatter plot. Here, we can view the data and there appears to be a straight line (linear) trend between height and weight. The association (or correlation) is positive. That means, that there is a weight increase with height. The Pearson correlation coefficient in this case was r = 0.56.

A type I error is made by rejecting a null hypothesis that is true. This means that there was no difference but the researcher concluded that the hypothesis was true.
A type II error is made by accepting that the null hypothesis is true when, in fact, it was false. Meaning there was actually a difference but the researcher did not think their hypothesis was supported.
Hypothesis Testing Procedures : In a general sense, the overall testing of a hypothesis has a systematic methodology. Remember, a hypothesis is an educated guess about the outcome. If we guess wrong, we might set up the tests incorrectly and might get results that are invalid. Sometimes, this is super difficult to get right. The main purpose of statistics is to test a hypothesis.
- Selecting a statistical test. Lots of factors go into this, including levels of measurement of the variables.
- Specifying the level of significance. Usually 0.05 is chosen.
- Computing a test statistic. Lots of software programs to help with this.
- Determining degrees of freedom ( df ). This refers to the number of observations free to vary about a parameter. Computing this is easy (but you don’t need to know how for this course).
- Comparing the test statistic to a theoretical value. Theoretical values exist for all test statistics, which is compared to the study statistics to help establish significance.
Some of the common inferential statistics you will see include:
Comparison tests: Comparison tests look for differences among group means. They can be used to test the effect of a categorical variable on the mean value of some other characteristic.
T-tests are used when comparing the means of precisely two groups (e.g., the average heights of men and women). ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults).
- t -tests (compares differences in two groups) – either paired t-test (example: What is the effect of two different test prep programs on the average exam scores for students from the same class?) or independent t-test (example: What is the difference in average exam scores for students from two different schools?)
- analysis of variance (ANOVA, which compares differences in three or more groups) (example: What is the difference in average pain levels among post-surgical patients given three different painkillers?) or MANOVA (compares differences in three or more groups, and 2 or more outcomes) (example: What is the effect of flower species on petal length, petal width, and stem length?)
Correlation tests: Correlation tests check whether variables are related without hypothesizing a cause-and-effect relationship.
- Pearson r (measures the strength and direction of the relationship between two variables) (example: How are latitude and temperature related?)
Nonparametric tests: Non-parametric tests don’t make as many assumptions about the data, and are useful when one or more of the common statistical assumptions are violated. However, the inferences they make aren’t as strong as with parametric tests.
- chi-squared ( X 2 ) test (measures differences in proportions). Chi-square tests are often used to test hypotheses. The chi-square statistic compares the size of any discrepancies between the expected results and the actual results, given the size of the sample and the number of variables in the relationship. For example, the results of tossing a fair coin meet these criteria. We can apply a chi-square test to determine which type of candy is most popular and make sure that our shelves are well stocked. Or maybe you’re a scientist studying the offspring of cats to determine the likelihood of certain genetic traits being passed to a litter of kittens.
Inferential Versus Descriptive Statistics Summary Table
Statistical Significance Versus Clinical Significance
Finally, when it comes to statistical significance in hypothesis testing, the normal probability value in nursing is <0.05. A p=value (probability) is a statistical measurement used to validate a hypothesis against measured data in the study. Meaning, it measures the likelihood that the results were actually observed due to the intervention, or if the results were just due by chance. The p-value, in measuring the probability of obtaining the observed results, assumes the null hypothesis is true.
The lower the p-value, the greater the statistical significance of the observed difference.
In the example earlier about our diabetic patients receiving online diet education, let’s say we had p = 0.05. Would that be a statistically significant result?
If you answered yes, you are correct!
What if our result was p = 0.8?
Not significant. Good job!
That’s pretty straightforward, right? Below 0.05, significant. Over 0.05 not significant.
Could we have significance clinically even if we do not have statistically significant results? Yes. Let’s explore this a bit.
Statistical hypothesis testing provides little information for interpretation purposes. It’s pretty mathematical and we can still get it wrong. Additionally, attaining statistical significance does not really state whether a finding is clinically meaningful. With a large enough sample, even a small very tiny relationship may be statistically significant. But, clinical significance is the practical importance of research. Meaning, we need to ask what the palpable effects may be on the lives of patients or healthcare decisions.
Remember, hypothesis testing cannot prove. It also cannot tell us much other than “yeah, it’s probably likely that there would be some change with this intervention”. Hypothesis testing tells us the likelihood that the outcome was due to an intervention or influence and not just by chance. Also, as nurses and clinicians, we are not concerned with a group of people – we are concerned at the individual, holistic level. The goal of evidence-based practice is to use best evidence for decisions about specific individual needs.
Additionally, begin your Discussion section. What are the implications to practice? Is there little evidence or a lot? Would you recommend additional studies? If so, what type of study would you recommend, and why?
- Were all the important results discussed?
- Did the researchers discuss any study limitations and their possible effects on the credibility of the findings? In discussing limitations, were key threats to the study’s validity and possible biases reviewed? Did the interpretations take limitations into account?
- What types of evidence were offered in support of the interpretation, and was that evidence persuasive? Were results interpreted in light of findings from other studies?
- Did the researchers make any unjustifiable causal inferences? Were alternative explanations for the findings considered? Were the rationales for rejecting these alternatives convincing?
- Did the interpretation consider the precision of the results and/or the magnitude of effects?
- Did the researchers draw any unwarranted conclusions about the generalizability of the results?
- Did the researchers discuss the study’s implications for clinical practice or future nursing research? Did they make specific recommendations?
- If yes, are the stated implications appropriate, given the study’s limitations and the magnitude of the effects as well as evidence from other studies? Are there important implications that the report neglected to include?
- Did the researchers mention or assess clinical significance? Did they make a distinction between statistical and clinical significance?
- If clinical significance was examined, was it assessed in terms of group-level information (e.g., effect sizes) or individual-level results? How was clinical significance operationalized?
References & Attribution
“ Green check mark ” by rawpixel licensed CC0 .
“ Magnifying glass ” by rawpixel licensed CC0
“ Orange flame ” by rawpixel licensed CC0 .
Polit, D. & Beck, C. (2021). Lippincott CoursePoint Enhanced for Polit’s Essentials of Nursing Research (10th ed.). Wolters Kluwer Health
Vaid, N. K. (2019) Statistical performance measures. Medium. https://neeraj-kumar-vaid.medium.com/statistical-performance-measures-12bad66694b7
Evidence-Based Practice & Research Methodologies Copyright © by Tracy Fawns is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Work With Us
Private Coaching
Done-For-You
Short Courses
Client Reviews
Free Resources
Quantitative Data Analysis 101
The Lingo, Methods and Techniques – Explained Simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones. On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones. But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post . What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other. Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Learn More About Quantitative:

Triangulation: The Ultimate Credibility Enhancer
Triangulation is one of the best ways to enhance the credibility of your research. Learn about the different options here.

Inferential Statistics 101: Simple Explainer (With Examples)
Learn about the key concepts and tests within inferential statistics, including t-tests, ANOVA, chi-square, correlation and regression.

Descriptive Statistics 101: Simple Explainer (With Examples)
Learn about the key concepts and measures within descriptive statistics, including measures of central tendency and dispersion.

Validity & Reliability: Explained Simply
Learn about validity and reliability within the context of research methodology. Plain-language explainer video with loads of examples.

Research Design 101: Qualitative & Quantitative
Learn about research design for both qualitative and quantitative studies. Includes plain-language explanations and examples.
📄 FREE TEMPLATES
Research Topic Ideation
Proposal Writing
Literature Review
Methodology & Analysis
Academic Writing
Referencing & Citing
Apps, Tools & Tricks
The Grad Coach Podcast
78 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Very useful, I have got the concept

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.

its nice work and excellent job ,you have made my work easier

Wow! So explicit. Well done.

This explanation is very clear and straight forward. Excellent job!
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Submit Comment
- Print Friendly
Are you an agency specialized in UX, digital marketing, or growth? Join our Partner Program
Learn / Guides / Quantitative data analysis guide
Back to guides
8 quantitative data analysis methods to turn numbers into insights
Setting up a few new customer surveys or creating a fresh Google Analytics dashboard feels exciting…until the numbers start rolling in. You want to turn responses into a plan to present to your team and leaders—but which quantitative data analysis method do you use to make sense of the facts and figures?
Last updated
Reading time.

This guide lists eight quantitative research data analysis techniques to help you turn numeric feedback into actionable insights to share with your team and make customer-centric decisions.
To pick the right technique that helps you bridge the gap between data and decision-making, you first need to collect quantitative data from sources like:
Google Analytics
Survey results
On-page feedback scores
Fuel your quantitative analysis with real-time data
Use Hotjar’s tools to collect quantitative data that helps you stay close to customers.
Then, choose an analysis method based on the type of data and how you want to use it.
Descriptive data analysis summarizes results—like measuring website traffic—that help you learn about a problem or opportunity. The descriptive analysis methods we’ll review are:
Multiple choice response rates
Response volume over time
Net Promoter Score®
Inferential data analyzes the relationship between data—like which customer segment has the highest average order value—to help you make hypotheses about product decisions. Inferential analysis methods include:
Cross-tabulation
Weighted customer feedback
You don’t need to worry too much about these specific terms since each quantitative data analysis method listed below explains when and how to use them. Let’s dive in!
1. Compare multiple-choice response rates
The simplest way to analyze survey data is by comparing the percentage of your users who chose each response, which summarizes opinions within your audience.
To do this, divide the number of people who chose a specific response by the total respondents for your multiple-choice survey. Imagine 100 customers respond to a survey about what product category they want to see. If 25 people said ‘snacks’, 25% of your audience favors that category, so you know that adding a snacks category to your list of filters or drop-down menu will make the purchasing process easier for them.
💡Pro tip: ask open-ended survey questions to dig deeper into customer motivations.
A multiple-choice survey measures your audience’s opinions, but numbers don’t tell you why they think the way they do—you need to combine quantitative and qualitative data to learn that.
One research method to learn about customer motivations is through an open-ended survey question. Giving customers space to express their thoughts in their own words—unrestricted by your pre-written multiple-choice questions—prevents you from making assumptions.
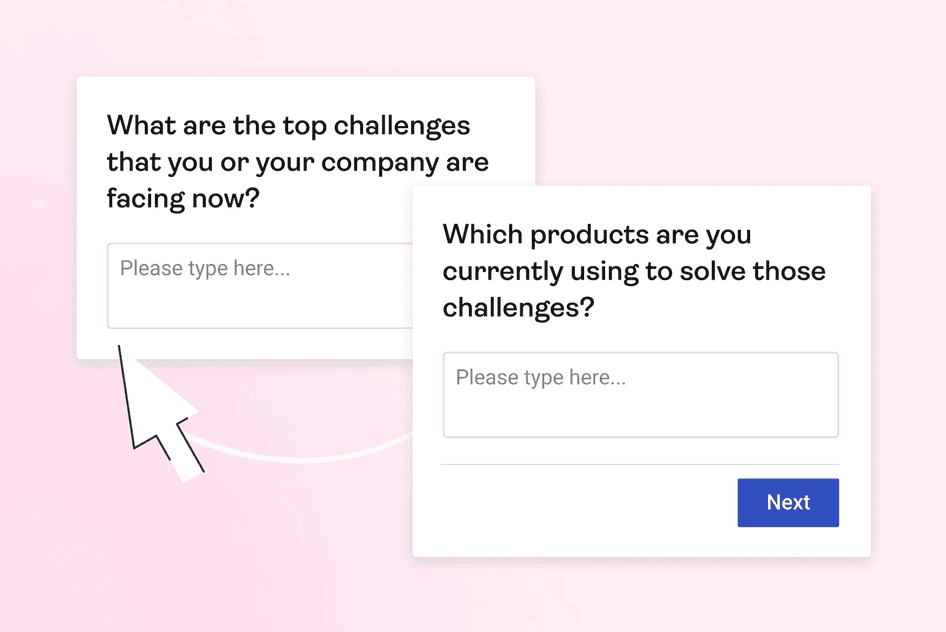
Hotjar’s open-ended surveys have a text box for customers to type a response
2. Cross-tabulate to compare responses between groups
To understand how responses and behavior vary within your audience, compare your quantitative data by group. Use raw numbers, like the number of website visitors, or percentages, like questionnaire responses, across categories like traffic sources or customer segments.

Let’s say you ask your audience what their most-used feature is because you want to know what to highlight on your pricing page. Comparing the most common response for free trial users vs. established customers lets you strategically introduce features at the right point in the customer journey .
💡Pro tip: get some face-to-face time to discover nuances in customer feedback.
Rather than treating your customers as a monolith, use Hotjar to conduct interviews to learn about individuals and subgroups. If you aren’t sure what to ask, start with your quantitative data results. If you notice competing trends between customer segments, have a few conversations with individuals from each group to dig into their unique motivations.
Hotjar Engage lets you identify specific customer segments you want to talk to
Mode is the most common answer in a data set, which means you use it to discover the most popular response for questions with numeric answer options. Mode and median (that's next on the list) are useful to compare to the average in case responses on extreme ends of the scale (outliers) skew the outcome.
Let’s say you want to know how most customers feel about your website, so you use an on-page feedback widget to collect ratings on a scale of one to five.

If the mode, or most common response, is a three, you can assume most people feel somewhat positive. But suppose the second-most common response is a one (which would bring the average down). In that case, you need to investigate why so many customers are unhappy.
💡Pro tip: watch recordings to understand how customers interact with your website.
So you used on-page feedback to learn how customers feel about your website, and the mode was two out of five. Ouch. Use Hotjar Recordings to see how customers move around on and interact with your pages to find the source of frustration.
Hotjar Recordings lets you watch individual visitors interact with your site, like how they scroll, hover, and click
Median reveals the middle of the road of your quantitative data by lining up all numeric values in ascending order and then looking at the data point in the middle. Use the median method when you notice a few outliers that bring the average up or down and compare the analysis outcomes.
For example, if your price sensitivity survey has outlandish responses and you want to identify a reasonable middle ground of what customers are willing to pay—calculate the median.
💡Pro-tip: review and clean your data before analysis.
Take a few minutes to familiarize yourself with quantitative data results before you push them through analysis methods. Inaccurate or missing information can complicate your calculations, and it’s less frustrating to resolve issues at the start instead of problem-solving later.
Here are a few data-cleaning tips to keep in mind:
Remove or separate irrelevant data, like responses from a customer segment or time frame you aren’t reviewing right now
Standardize data from multiple sources, like a survey that let customers indicate they use your product ‘daily’ vs. on-page feedback that used the phrasing ‘more than once a week’
Acknowledge missing data, like some customers not answering every question. Just note that your totals between research questions might not match.
Ensure you have enough responses to have a statistically significant result
Decide if you want to keep or remove outlying data. For example, maybe there’s evidence to support a high-price tier, and you shouldn’t dismiss less price-sensitive respondents. Other times, you might want to get rid of obviously trolling responses.
5. Mean (AKA average)
Finding the average of a dataset is an essential quantitative data analysis method and an easy task. First, add all your quantitative data points, like numeric survey responses or daily sales revenue. Then, divide the sum of your data points by the number of responses to get a single number representing the entire dataset.
Use the average of your quant data when you want a summary, like the average order value of your transactions between different sales pages. Then, use your average to benchmark performance, compare over time, or uncover winners across segments—like which sales page design produces the most value.
💡Pro tip: use heatmaps to find attention-catching details numbers can’t give you.
Calculating the average of your quant data set reveals the outcome of customer interactions. However, you need qualitative data like a heatmap to learn about everything that led to that moment. A heatmap uses colors to illustrate where most customers look and click on a page to reveal what drives (or drops) momentum.
Hotjar Heatmaps uses color to visualize what most visitors see, ignore, and click on
6. Measure the volume of responses over time
Some quantitative data analysis methods are an ongoing project, like comparing top website referral sources by month to gauge the effectiveness of new channels. Analyzing the same metric at regular intervals lets you compare trends and changes.
Look at quantitative survey results, website sessions, sales, cart abandons, or clicks regularly to spot trouble early or monitor the impact of a new initiative.
Here are a few areas you can measure over time (and how to use qualitative research methods listed above to add context to your results):
7. Net Promoter Score®
Net Promoter Score® ( NPS ®) is a popular customer loyalty and satisfaction measurement that also serves as a quantitative data analysis method.
NPS surveys ask customers to rate how likely they are to recommend you on a scale of zero to ten. Calculate it by subtracting the percentage of customers who answer the NPS question with a six or lower (known as ‘detractors’) from those who respond with a nine or ten (known as ‘promoters’). Your NPS score will fall between -100 and 100, and you want a positive number indicating more promoters than detractors.

💡Pro tip : like other quantitative data analysis methods, you can review NPS scores over time as a satisfaction benchmark. You can also use it to understand which customer segment is most satisfied or which customers may be willing to share their stories for promotional materials.
Review NPS score trends with Hotjar to spot any sudden spikes and benchmark performance over time
8. Weight customer feedback
So far, the quantitative data analysis methods on this list have leveraged numeric data only. However, there are ways to turn qualitative data into quantifiable feedback and to mix and match data sources. For example, you might need to analyze user feedback from multiple surveys.
To leverage multiple data points, create a prioritization matrix that assigns ‘weight’ to customer feedback data and company priorities and then multiply them to reveal the highest-scoring option.
Let’s say you identify the top four responses to your churn survey . Rate the most common issue as a four and work down the list until one—these are your customer priorities. Then, rate the ease of fixing each problem with a maximum score of four for the easy wins down to one for difficult tasks—these are your company priorities. Finally, multiply the score of each customer priority with its coordinating company priority scores and lead with the highest scoring idea.
💡Pro-tip: use a product prioritization framework to make decisions.
Try a product prioritization framework when the pressure is on to make high-impact decisions with limited time and budget. These repeatable decision-making tools take the guesswork out of balancing goals, customer priorities, and team resources. Four popular frameworks are:
RICE: weighs four factors—reach, impact, confidence, and effort—to weigh initiatives differently
MoSCoW: considers stakeholder opinions on 'must-have', 'should-have', 'could-have', and 'won't-have' criteria
Kano: ranks ideas based on how likely they are to satisfy customer needs
Cost of delay analysis: determines potential revenue loss by not working on a product or initiative
Share what you learn with data visuals
Data visualization through charts and graphs gives you a new perspective on your results. Plus, removing the clutter of the analysis process helps you and stakeholders focus on the insight over the method.
Data visualization helps you:
Get buy-in with impactful charts that summarize your results
Increase customer empathy and awareness across your company with digestible insights
Use these four data visualization types to illustrate what you learned from your quantitative data analysis:
Bar charts reveal response distribution across multiple options
Line graphs compare data points over time
Scatter plots showcase how two variables interact
Matrices contrast data between categories like customer segments, product types, or traffic source

Use a variety of customer feedback types to get the whole picture
Quantitative data analysis pulls the story out of raw numbers—but you shouldn’t take a single result from your data collection and run with it. Instead, combine numbers-based quantitative data with descriptive qualitative research to learn the what, why, and how of customer experiences.
Looking at an opportunity from multiple angles helps you make more customer-centric decisions with less guesswork.
Stay close to customers with Hotjar
Hotjar’s tools offer quantitative and qualitative insights you can use to make customer-centric decisions, get buy-in, and highlight your team’s impact.
Frequently asked questions about quantitative data analysis
What is quantitative data.
Quantitative data is numeric feedback and information that you can count and measure. For example, you can calculate multiple-choice response rates, but you can’t tally a customer’s open-ended product feedback response. You have to use qualitative data analysis methods for non-numeric feedback.
What are quantitative data analysis methods?
Quantitative data analysis either summarizes or finds connections between numerical data feedback. Here are eight ways to analyze your online business’s quantitative data:
Compare multiple-choice response rates
Cross-tabulate to compare responses between groups
Measure the volume of response over time
Net Promoter Score
Weight customer feedback
How do you visualize quantitative data?
Data visualization makes it easier to spot trends and share your analysis with stakeholders. Bar charts, line graphs, scatter plots, and matrices are ways to visualize quantitative data.
What are the two types of statistical analysis for online businesses?
Quantitative data analysis is broken down into two analysis technique types:
Descriptive statistics summarize your collected data, like the number of website visitors this month
Inferential statistics compare relationships between multiple types of quantitative data, like survey responses between different customer segments
Quantitative data analysis process
Previous chapter
Quantitative data analysis software
Next chapter
Data Analysis in Quantitative Research
- Reference work entry
- First Online: 13 January 2019
- Cite this reference work entry

- Yong Moon Jung 2
2502 Accesses
2 Citations
Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility. Conducting quantitative data analysis requires a prerequisite understanding of the statistical knowledge and skills. It also requires rigor in the choice of appropriate analysis model and the interpretation of the analysis outcomes. Basically, the choice of appropriate analysis techniques is determined by the type of research question and the nature of the data. In addition, different analysis techniques require different assumptions of data. This chapter provides introductory guides for readers to assist them with their informed decision-making in choosing the correct analysis models. To this end, it begins with discussion of the levels of measure: nominal, ordinal, and scale. Some commonly used analysis techniques in univariate, bivariate, and multivariate data analysis are presented for practical examples. Example analysis outcomes are produced by the use of SPSS (Statistical Package for Social Sciences).
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Data Analysis Techniques for Quantitative Study

Meta-Analytic Methods for Public Health Research
Armstrong JS. Significance tests harm progress in forecasting. Int J Forecast. 2007;23(2):321–7.
Article Google Scholar
Babbie E. The practice of social research. 14th ed. Belmont: Cengage Learning; 2016.
Google Scholar
Brockopp DY, Hastings-Tolsma MT. Fundamentals of nursing research. Boston: Jones & Bartlett; 2003.
Creswell JW. Research design: qualitative, quantitative, and mixed methods approaches. Thousand Oaks: Sage; 2014.
Fawcett J. The relationship of theory and research. Philadelphia: F. A. Davis; 1999.
Field A. Discovering statistics using IBM SPSS statistics. London: Sage; 2013.
Grove SK, Gray JR, Burns N. Understanding nursing research: building an evidence-based practice. 6th ed. St. Louis: Elsevier Saunders; 2015.
Hair JF, Black WC, Babin BJ, Anderson RE, Tatham RD. Multivariate data analysis. Upper Saddle River: Pearson Prentice Hall; 2006.
Katz MH. Multivariable analysis: a practical guide for clinicians. Cambridge: Cambridge University Press; 2006.
Book Google Scholar
McHugh ML. Scientific inquiry. J Specialists Pediatr Nurs. 2007; 8 (1):35–7. Volume 8, Issue 1, Version of Record online: 22 FEB 2007
Pallant J. SPSS survival manual: a step by step guide to data analysis using IBM SPSS. Sydney: Allen & Unwin; 2016.
Polit DF, Beck CT. Nursing research: principles and methods. Philadelphia: Lippincott Williams & Wilkins; 2004.
Trochim WMK, Donnelly JP. Research methods knowledge base. 3rd ed. Mason: Thomson Custom Publishing; 2007.
Tabachnick, B. G., & Fidell, L. S. (2013). Using multivariate statistics. Boston: Pearson Education.
Wells CS, Hin JM. Dealing with assumptions underlying statistical tests. Psychol Sch. 2007;44(5):495–502.
Download references
Author information
Authors and affiliations.
Centre for Business and Social Innovation, University of Technology Sydney, Ultimo, NSW, Australia
Yong Moon Jung
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Yong Moon Jung .
Editor information
Editors and affiliations.
School of Science and Health, Western Sydney University, Penrith, NSW, Australia
Pranee Liamputtong
Rights and permissions
Reprints and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this entry
Cite this entry.
Jung, Y.M. (2019). Data Analysis in Quantitative Research. In: Liamputtong, P. (eds) Handbook of Research Methods in Health Social Sciences. Springer, Singapore. https://doi.org/10.1007/978-981-10-5251-4_109
Download citation
DOI : https://doi.org/10.1007/978-981-10-5251-4_109
Published : 13 January 2019
Publisher Name : Springer, Singapore
Print ISBN : 978-981-10-5250-7
Online ISBN : 978-981-10-5251-4
eBook Packages : Social Sciences Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
Share this entry
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
IMAGES
COMMENTS
Quantitative Research. Quantitative research is a research approach that seeks to quantify data and generalize results from a sample to a larger population. It relies on structured data collection methods and employs statistical analysis to interpret results. This type of research is objective, and findings are typically presented in numerical ...
Quantitative Analysis. Description: Quantitative data analysis is a high-level branch of data analysis that designates methods and techniques concerned with numbers instead of words. It accounts for more than 50% of all data analysis and is by far the most widespread and well-known type of data analysis.
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis: Step 1: Data Collection. Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as ...
Analysis of Quantitative Data in Quantitative Research. Analyzing quantitative data in quantitative research involves a systematic process of examining numerical information to uncover patterns, relationships, and insights that address specific research questions or objectives. Here’s a structured overview of the analysis process:
Types of Data Analysis. Data analysis can be separated and organized into types, arranged in an increasing order of complexity. 1. Descriptive Analysis. The goal of descriptive analysis is to describe or summarize a set of data. Here’s what you need to know: Descriptive analysis is the very first analysis performed in the data analysis process.
Methods used for data analysis in quantitative research. After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data.
Data Analysis Methods in Quantitative Research We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim).
Quantitative Data Analysis 101. The Lingo, Methods and Techniques – Explained Simply. Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo, like medians, modes, correlation and regression.
Quantitative data analysis is broken down into two analysis technique types: Descriptive statistics summarize your collected data, like the number of website visitors this month. Inferential statistics compare relationships between multiple types of quantitative data, like survey responses between different customer segments
Abstract. Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility.